
Project URL: https://github.com/Insignite/SVM-Food101-Classification
This project is my part taken from the main project GitHub food_classification. I’ve done two deep learning algorithms, SSD Inception v2 for Card 9-A Object Detection and AlexNet architecture for DogvsCat Classification, so I would like to dive deeper into the Machine learning field by working on an algorithm even earlier than AlexNet. Support Vector Machines (SVM) for multiclass classification seems fun so I decided to go with it.
Introduction
Support Vector Machines (SVM) is a supervised learning model with associated algorithms that analyzes data by plotting data points on N-dimensionals graph (N is the number of features) and performs classification by drawing an optimal hyperplane. Data points that closer to the hyperplane influence the position and the orientation of the hyperplane. With this information, we can optimize the hyperplane by fine tuning Cost (C) and Gradient (g = gamma substitute variable). Large Cdecreases the margin of the hyperplane, which allow much less misclassified points and lead to hyperplane attemp to fit as many point as possible, where as small C allows more generalization and smoother hyperplane. For g, a higher value leads to a lower Ecludien distance between data points and scale down fit area.
Dataset
Food-101 is a large dataset consist of 1000 images for 101 type of food. Each images have a range of dimension from 318×318 to 512×512.

For linux user, extract the download dataset. For windows user, just use compress file extractor like WinRAR.
tar xzvf food-101.tar.gzDataset Structure
food-101
|_ images
|_ ***CLASSES FOLDER***
|_ ***IMAGE BELONG TO THE PARENT CLASSES***
|_ meta
|_ classes.txt
|_train.json
|_ train.txt
|_ test.json
|_ test.txt
|_ labels.txt
|_ license_agreement.txt
|_ README.txtDataset Classes
apple_pie eggs_benedict onion_rings
baby_back_ribs escargots oysters
baklava falafel pad_thai
beef_carpaccio filet_mignon paella
beef_tartare fish_and_chips pancakes
beet_salad foie_gras panna_cotta
beignets french_fries peking_duck
bibimbap french_onion_soup pho
bread_pudding french_toast pizza
breakfast_burrito fried_calamari pork_chop
bruschetta fried_rice poutine
caesar_salad frozen_yogurt prime_rib
cannoli garlic_bread pulled_pork_sandwich
caprese_salad gnocchi ramen
carrot_cake greek_salad ravioli
ceviche grilled_cheese_sandwich red_velvet_cake
cheesecake grilled_salmon risotto
cheese_plate guacamole samosa
chicken_curry gyoza sashimi
chicken_quesadilla hamburger scallops
chicken_wings hot_and_sour_soup seaweed_salad
chocolate_cake hot_dog shrimp_and_grits
chocolate_mousse huevos_rancheros spaghetti_bolognese
churros hummus spaghetti_carbonara
clam_chowder ice_cream spring_rolls
club_sandwich lasagna steak
crab_cakes lobster_bisque strawberry_shortcake
creme_brulee lobster_roll_sandwich sushi
croque_madame macaroni_and_cheese tacos
cup_cakes macarons takoyaki
deviled_eggs miso_soup tiramisu
donuts mussels tuna_tartare
dumplings nachos waffles
edamame omelette
Dataset Approach
In this project, I will only do classification for noodle classes as I have limited resource for training and testing. There are 5 noodle classes total:
['pad_thai', 'pho', 'ramen', 'spaghetti_bolognese', 'spaghetti_carbonara']
With 5 classes, I have 5000 images total. train.json and test.json splitted into 3750 and 1250 respectively.
Let’s load in the data through train.json. But first let’s look at how the data labeled.
(Below is a very small scale of train.json content for ONLY 5 classes I am targeting. Original train.json will have all 101 classes)
{
"pad_thai": ["pad_thai/2735021", "pad_thai/3059603", "pad_thai/3089593", "pad_thai/3175157", "pad_thai/3183627"],
"ramen": ["ramen/2487409", "ramen/3003899", "ramen/3288667", "ramen/3570678", "ramen/3658881"],
"spaghetti_bolognese": ["spaghetti_bolognese/2944432", "spaghetti_bolognese/2969047", "spaghetti_bolognese/3087717", "spaghetti_bolognese/3153075", "spaghetti_bolognese/3659120"],
"spaghetti_carbonara": ["spaghetti_carbonara/2610045", "spaghetti_carbonara/2626986", "spaghetti_carbonara/3149149", "spaghetti_carbonara/3516580", "spaghetti_carbonara/3833174"],
"pho": ["pho/2599236", "pho/2647478", "pho/2654197", "pho/2696250", "pho/2715359"]
}
SVM parameters required a label list and feature list. So I will load data from train.json into a data frame and create a feature list for both HOG and Transfer learning.
Train Dataframe
filename label
0 1004763.jpg 0
1 1009595.jpg 0
2 1011059.jpg 0
3 1011238.jpg 0
4 1013966.jpg 0
... ... ...
3745 977656.jpg 4
3746 980577.jpg 4
3747 981334.jpg 4
3748 991708.jpg 4
3749 992617.jpg 4
[3750 rows x 2 columns]
HOG Train Feature Shape with PCA
(3750, 1942)
Transfer Learning Train Feature Shape
(3750, 6400)
Training
Training Approach
I built a SVM classification with two approach:
Histogram of Oriented Gradients (HOG)

By using HOG, it shows that HOG image able to keep the shape of objects very well which allow for edge detection. The input images will get reshape to 227x227x3 (A higher amount of pixel input makes training much slower yet increase the accuracy). I also applied Principal Component Analysis (PCA). It is a method used to reduce the number of features (aka reduction in dimensions) in the data by extracting the important data points while retaining as much information as possible.
Transfer Learning
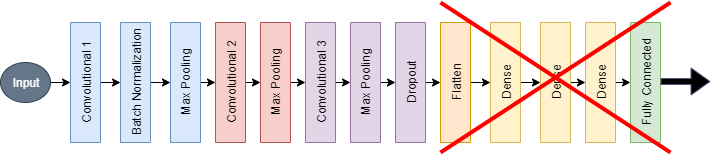
The transfer learning technique is a method that uses the pre-trained model to build a new custom model or perform feature extraction. In this project, I will use a pre-trained AlexNet model from my teammate for feature extraction. AlexNet input is always 227x227x3 so I will reshape all images to this dimension. I built a new model with all layers of my teammate AlexNet until flatten layer(Displayed in the figure), which gives an output of 5x5x256 = 6400 training features.
Training parameters
SVM has three important parameters we should wary about: Kernel type, C, and g (C and g explanation in Introduction section). Kernel type very much depends if the data points are linearly separable. Let’s plot 151 images with their first 2 features out of 6400 features into the different kernel of SVM. All three plot will have C = 0.5 and g = 2.
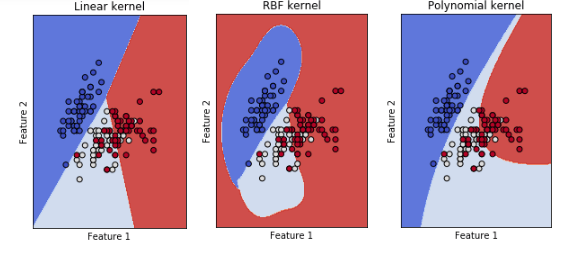
It seems like the data points able to classify decently well with all three kernels, but this is only the first 2 features. What if we plot all 6400 features? There will definitely an kernel out perform others.There are still C and g that I can adjust to optimize the hyperplane. Let’s take a look of various C and g plot.


With so many way C and g can tune the hyperplane, how can we find the optimal combination? Let’s do something called Grid searching, essentially is running cross validation for all possible combination of Kernel, C, and g on certain range. According to A Practical Guide to Support Vector Classification paper, exponential growing of C and g give the best result. I will use the paper recommended range C = 2-5, 2-3, … ,215 and g = 2-15, 2-13, … , 23. With all three parameters, I able to create 396 combinations. Below if a sample of small combination runs.

After 396 cross validations run with different parameters, the parameter with highest accuracy is Kernel = Linear, C = 0.5, and g = 2. Now we are ready to train our model.
Training Model
I initially use Scikit-Learn to train an SVM model, but it takes extremely long for an unknown reason. To this day I still don’t know why. Stumble upon a suggestion, I switched over to LIBSVM and able to increase training time significantly.
Result
Histogram of Oriented Gradients (HOG)
- Traing Validation Accuracy: 81.0%
- Test Accuracy: 96.0%Transfer Learning
- Cross Validation Accuracy: 57%
- Test Accuracy: 68.2%
Conclusion
HOG approach has much higher accuracy compared to the Transfer learning approach. This is within my expectation because Transfer learning on the AlexNet model required input images to go through a series of filters, which lead to loss of detail and reduction in features. My prediction is that if the Transfer learning approach taking earlier layers, rather than taken up to the last Convolutional layer of AlexNet, the accuracy would be better because layers toward the beginning of AlexNet architecture given much more features than later layers.